在高并发的系统中,我们常采用多数据库分散放置、读写分离、细粒度的隔离级别设定等策略来提高系统的性能。DataRabbit3.3 以及以上版本对这三种策略都给予了内置的支持。
(1)数据库分散放置:对于较大型的系统,在设计数据库时,我们可以根据业务范围将其设计为多个数据库,而不是一个,然后将这些数据库部署在不同的物理服务器上,以分担负载。当然,如果已经设计好的数据库,也可以采用水平分区或垂直分区的方式来达到类似的效果。
(2)读写分离:在高性能的系统中,这是最常采用的策略。在SqlServer中,可以采用事务型的订阅/发布模型来实现这种策略。在这种策略中,有一个Master DB 和多个(或一个)Slave DB,其中所有的Slave DB是只读的,而Master DB支持读写,当Master DB中的数据发生变化时,所有Slave DB会自动与其同步(可能会有稍微的延迟)。
(3)细粒度的隔离级别:比如,对于某些要求不高的查询可以采用ReadUncommitted的隔离级别来读取数据。
DataRabbit.Application.TransactionScopeFactoryProvider<TSourceKey,TSlaveSuitKey> 类可以支持数据库分散放置和读写分离。它支持【1套主/N套从】数据库实例。 【一套】表示支持一个系统运行的不可或缺的相互协作的多个数据库。
TransactionScopeFactoryProvider类图结构如下所示:
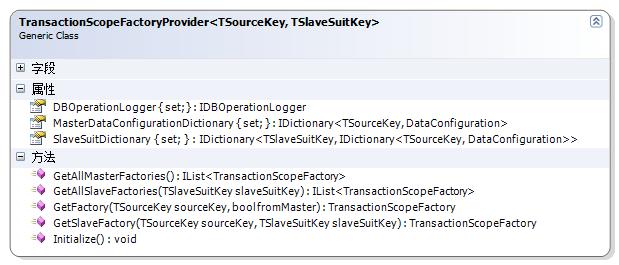
其中泛型参数TSourceKey是用来表示数据源标志的类型,比如我们可以用字符串来为每个数据库(数据源)命名,那么TSourceKey便可使用string类型。
泛型参数TSlaveSuitKey是用来表示每套从库的【套标志】的类型,比如,我们每套Slave库中包含5个数据库(这与Master中的5个是一一对应的),而我们可以提供比如3套Slave库以支持超大负载的数据读取,于是我们就要为这三套Slave库加以不同的标志以区分。
其中有用于注入Master DB数据库连接信息的Dictionary属性:MasterDataConfigurationDictionary,键便是TSourceKey类型,是每个数据源的标志,其值是用于封装数据库连接信息的DataConfiguration,这个类大家已经很熟悉了。而SlaveSuitDictionary用于注入多套从库的数据库连接信息。当然你已经知道,MasterDataConfigurationDictionary和SlaveSuitDictionary中每一套的项是一一对应的。还有一个小技巧,如果你现在的系统还不够大,但是以后会采用倒读写分离策略,那么暂时你可以将Master和Slave配置为指向同一个数据库,这是没有问题的,等系统做大了以上,需要Slave的支持时,只要修改一下配置即可。
DBOperationLogger属性用于记录数据库的所有操作和访问产生的异常信息。如果不设置,则表示不记录这些信息,关于DBOperationLogger的介绍,可以参考这里。
接下来我们再看GetFactory方法:
<!--<br /><br />Code highlighting produced by Actipro CodeHighlighter (freeware)<br />http://www.CodeHighlighter.com/<br /><br />-->TransactionScopeFactoryGetFactory(TSourceKeysourceKey,boolfromMaster);
其第一个参数表示要访问哪个数据库,第二个参数表示是要访问Master库还是Slave库。我们要注意到,当系统采用多套从库时,GetFactory()方法会随机的返回某套从库的TransactionScopeFactory,从而达到自动负载均衡的目的。当然你也可以通过GetSlaveFactory()方法来返回指定标志的某套从库的TransactionScopeFactory。
如此,我们可以这样来使用读写分离机制 -- 比如,我们有一个任务只是读取数据库,而不会有任何修改行为,那么就从Slave库中读取:
<!--<br /><br />Code highlighting produced by Actipro CodeHighlighter (freeware)<br />http://www.CodeHighlighter.com/<br /><br />-->IList<Student>list=null;
TransactionScopeFactoryfactory=this.transactionScopeFactoryProvider.GetFactory(DBSourceType.Basic,false);
using(TransactionScopescope=factory.NewTransactionScope(false))
{
IOrmAccesser<Student>accesser=scope.NewOrmAccesser<Student>();
list=accesser.GetAll();
scope.Commit();
}
returnlist;
这个例子中,我们用一个枚举DBSourceType来标志多个数据源,例子从标志位Basic的数据源的Slave库中读取所有的Student列表信息。
接下来,我们来看对隔离级别的支持。
还是使用上面的这个例子,假设我们的业务允许读取Student列表可以为脏读,那么可以降低读取的隔离级别(默认为ReadCommitted):
<!--<br /><br />Code highlighting produced by Actipro CodeHighlighter (freeware)<br />http://www.CodeHighlighter.com/<br /><br />-->IList<Student>list=null;
TransactionScopeFactoryfactory=this.transactionScopeFactoryProvider.GetFactory(DBSourceType.Basic,false);
using(TransactionScopescope=factory.NewTransactionScope(false, IsolationLevel.ReadUncommitted))
{
IOrmAccesser<Student>accesser=scope.NewOrmAccesser<Student>();
list=accesser.GetAll();
scope.Commit();
}
returnlist;
IsolationLevel定义如下:
<!--<br /><br />Code highlighting produced by Actipro CodeHighlighter (freeware)<br />http://www.CodeHighlighter.com/<br /><br />-->publicenumIsolationLevel
{
ReadUncommitted=0,
ReadCommitted,
RepeatableRead,
Serializable
}
DataRabbit3.3及以上版本对上述策略都给予了充分的支持,你可以下载最新版本试试。
关于DataRabbit的更多信息目录,参见这里。
分享到:




相关推荐
构建高性能web之路------mysql读写分离实战.pdf
无痕驱动读写-破虚拟读写无痕驱动读写-破虚拟读写无痕驱动读写-破虚拟读写无痕驱动读写-破虚拟读写无痕驱动读写-破虚拟读写无痕驱动读写-破虚拟读写无痕驱动读写-破虚拟读写无痕驱动读写-破虚拟读写无痕驱动读写-破...
Sharding-JDBC教程:Spring Boot整合Sharding-JDBC实现读写分离
这几天因为工作需要,学习研究了一下spring-boot。spring-boot+mybatis+druid+读写分离+swagger进行一个整合,做了一个demo。自己已经充分测试,过程中也踩了不少的坑。
Sharding-JDBC实现读写分离demo
使用mysql-proxy实现mysql读写分离
LNH_MySQL 05-mysql数据库读写分离介绍及企业生产实现方案.mp4
spring-boot2+mybatis+druid+读写分离+swagger2进行一个整合,做了一个demo。自己已经充分测试,过程中也踩了不少的坑。 前两天刚上传一个demo。事物有点问题,非常抱歉。建议大家选择spring-boot 2.0版本以上,jdk8...
利用SpringBoot-mybatis实现读写分离。该代码是针对个人的docker 读写分离做的测试代码。
PHP轻量级数据库框架,PHP更简单高效的数据库操作方式
行业分类-设备装置-数据读写分离机制的实现方法和装置.zip
MySQL 读写分离 MySQL读写分离又一好办法 使用 com.mysql.jdbc.ReplicationDriver 在用过Amoeba 和 Cobar,还有dbware 等读写分离组件后,今天我的一个好朋友跟我讲,MySQL自身的也是可以读写分离的,因为他们提供了...
使用sharding-jdbc快速实现自动读写分离-demo源码!
1.Seconds_Behind_Master 不为了,这个值可能会很大 3.mysql 的 slave 数据库目录下存在大量的 mysql-relay-log
springboot+mybatis: 1,yml配置多个数据源 2,数据库主从配置 3,分包形式处理读写分离
1、基于springboot框架,application.yml配置多个数据源,使用AOP以及AbstractRootingDataSource、ThreadLocal来实现多数据源切换,以实现读写分离。mysql的主从数据库需要进行设置数据之间的同步。 2、AOP来实现...
NULL 博文链接:https://andyaqu.iteye.com/blog/2029993
DM 数据守护与读写分离集群DM 数据守护与读写分离集群DM 数据守护与读写分离集群DM 数据守护与读写分离集群